The Rise of LLM-Centric Architecture and MCP
Introduction
Modern software architecture is undergoing a deep paradigm shift. Traditional client/server (C/S) and browser/server (B/S) models centralized most logic and data on servers, with clients (desktop applications or browsers) primarily acting as interfaces.
Today, the emergence of Large Language Models (LLMs) as core components of applications is inverting that model: the “client” – often an AI agent powered by an LLM – is becoming an intelligent orchestrator that dynamically coordinates multiple services and data sources.
This report analyzes this pivot toward a client-centralized paradigm in the context of LLM-driven applications, focusing on the Model Context Protocol (MCP) as a key enabling standard. We will examine why MCP was invented, what problems it solves, and draw parallels to earlier integration innovations like SOAP and REST.
We also discuss how SOAP standardized server-to-server communication and how REST enabled scalable web interactions, then compare these to MCP’s approach of letting LLM clients seamlessly connect to external tools and data (servers). In doing so, we explore the technical motivations behind MCP, its role in LLM-centric architectures, the shift in trust and compute from back-end to front-end, and how LLMs now act as smart clients with stateless access to modular tools. Commentary from developers and companies adopting MCP is included, along with emerging standards and critiques surrounding this new approach.
Traditional Client/Server Models and Their Limits
In classic client/server (C/S) architecture, a desktop or mobile client interacts with a monolithic server. The server houses business logic, data storage, and integrative functions, while the client mainly handles presentation.
Browser/server (B/S) (web architecture) took this further by making the web browser a universal thin client and concentrating application logic on web servers. These models thrived in an era when keeping control on the server made sense: servers enforced security, aggregated data, and performed heavy computation, whereas clients were relatively static.
However, these paradigms also meant clients were dependent on servers for every complex operation or cross-system task. Integration between different servers or services was typically handled on the back-end, not by the client.
Over time, the web evolved toward richer client-side applications (e.g. single-page applications) that offloaded some work to the front-end. But even in those cases, the front-end code was explicitly programmed to call specific back-end APIs.
The intelligence (decision-making, data integration) still largely resided in server-defined APIs. Each integration between systems was custom – either hard-coded into the server, or requiring the client developer to manually invoke multiple APIs and combine results.
This approach started to show limitations as applications grew to rely on many disparate data sources and services, and as users demanded more real-time, context-rich experiences.
Large Language Models introduce a new factor:
An LLM-based client can interpret user intent and potentially decide on-the-fly which actions to take or which data to fetch.
This is a radically different role for a client. Instead of being told exactly what to request by pre-written code, an LLM-powered client can autonomously determine that:
“To answer the user’s query, I should fetch data from Service A and also perform action B.”
In the traditional architecture, such orchestration logic would live on a server (or require the developer to script it explicitly on the client).
With LLMs, we have for the first time a general-purpose reasoning engine running as part of the client side, capable of connecting the dots dynamically.
Evolution of Integration Protocols: SOAP and REST
The challenges of integrating multiple systems are not new. In the early 2000s, as web services proliferated, the industry faced a similar fragmentation problem: every service had its own conventions, making integration brittle. The introduction of SOAP (Simple Object Access Protocol) was a key milestone in creating standardized communication between servers. SOAP provided an XML-based messaging framework and typically used WSDL (Web Services Description Language) as an interface contract. This allowed any client or server that understood SOAP/WSDL to call any web service without custom parsing or ad-hoc agreements.
In essence, SOAP acted as a common language for web services, enabling applications built on different technologies to interact seamlessly. By defining services, data formats, and operations in a standard, machine-readable way, SOAP (with WSDL) improved interoperability and reduced integration effort. Developers could auto-generate client stubs from a WSDL, saving time and avoiding errors, which “eliminates the need for developers to spend time deciphering proprietary communication methods.”
This standardization of interfaces was analogous to establishing a postal system for software – everyone agreed on the “envelope” and address format (SOAP messages and endpoints), so messages could reliably be exchanged between any two systems. SOAP’s impact was especially felt in server-to-server integrations (e.g. enterprise applications communicating with each other) where strong typing, formal contracts, and security extensions (WS-Security) were valuable.
A few years later, RESTful APIs rose to prominence as a simpler, more scalable approach for web communication. REST (Representational State Transfer) is an architectural style that leverages the existing infrastructure of the web (HTTP verbs, URIs) and emphasizes stateless interactions and resources rather than operations.
RESTful APIs typically exchange lightweight JSON (or XML) over HTTP without the overhead of XML envelopes or strict WSDL schemas. This made them easier to use for web and mobile clients and better suited for internet scale.
The appeal of REST was in its simplicity and performance: it’s “lightweight and easy to understand” for developers, messages are typically much smaller and faster to process than SOAP’s XML, and it naturally fits the web paradigm. REST enabled massive scaling of web interactions – services could handle high volumes of requests from browsers or mobile apps by using stateless request/response patterns and caching where possible.
By the 2010s, RESTful APIs became the default way to expose web services, fostering an ecosystem where developers could integrate with external services quickly by following common REST conventions.
The success of REST underscores how a uniform, scalable interface can accelerate adoption: any developer who “speaks HTTP+JSON” can plug into any REST API, much like any web browser can talk to any website.
These two epochs – the SOAP/WSDL era and the RESTful API era – illustrate how standard protocols evolve to address integration pain points. SOAP addressed heterogeneity with a heavy-but-formal standard (ideal for enterprise back-ends), and REST addressed web scale with a lightweight approach (ideal for client-server interactions over the internet).
In both cases, the goal was to reduce the friction of connecting systems. MCP’s emergence today is analogous, but now the context is AI and tool integrations. Just as SOAP and REST arose to simplify and standardize interactions (albeit in different ways), MCP is a response to the growing complexity of connecting AI (LLM) “clients” with the myriad of tools and data they need access to.
LLM-Centric Architecture: The Client as Orchestrator
With advanced LLMs at the center of applications, we’re seeing the client take on a new orchestration role. An LLM-empowered client (such as an AI assistant in a chat app, or an “Agent” in an IDE or workflow tool) can dynamically decide which operations to perform and in what sequence. This is fundamentally different from a hard-coded sequence of API calls. The architectural balance is flipped – instead of a server coordinating calls to databases or external APIs and then sending results to a passive client, the LLM-driven client is actively making calls to various servers and then composing an answer or action for the user.
This inversion carries both opportunities and challenges. On one hand, the client (the AI) can provide very rich, context-aware behavior: it can integrate information from multiple sources on the fly, reason about it, and present a unified result to the user. The user’s device or client application essentially becomes a hub that taps into many services. On the other hand, it requires a way for the AI to know how to talk to those services (the integration problem), and it raises questions about security and trust (the governance problem). We are effectively shifting compute and decision-making from the back-end to the front-end. The heavy reasoning (and even some state management) happens in the client’s AI model, which might be running on the user’s machine or as a local application (or at least logically separated from the data servers). This means we now trust the client-side to orchestrate correctly and to enforce certain constraints. For example, in a client-orchestrator model, the client decides which data to fetch and how to use it – whereas in a traditional model, the server might decide what the client is allowed to see or do in a given flow.
Consider a concrete scenario: an AI coding assistant embedded in an IDE needs to:
- fetch documentation from an internal wiki,
- retrieve some code from a GitHub repository, and
- open a ticket in JIRA – all to help a developer accomplish a task via a single natural language request.
In a traditional model, you might build a back-end service that the IDE calls, and that back-end service has connectors to the wiki API, GitHub API, and JIRA API, orchestrating them and returning a result. In the new LLM-centric model, the IDE’s AI agent itself can directly call the wiki, GitHub, and JIRA, and then synthesize a solution. The orchestration logic lives in the AI’s “mind” (and the surrounding client code) rather than in a fixed back-end service. The client becomes the integration point for disparate services.
This shift introduces a need for standard interfaces that the AI agent (client) can use to communicate with various tools reliably. Without such standards, each new tool or data source would require custom prompting or custom code to interface with the LLM. Indeed, early attempts at LLM “agents” had developers writing one-off wrappers or prompts for every tool (e.g. a custom prompt telling the LLM how to call a weather API, another for a database query, etc.). This is analogous to the pre-SOAP days when every service integration was ad-hoc. It quickly becomes unscalable and brittle – as one author put it, integrating multiple tools with an AI agent can turn into “integration hell” of brittle APIs, manual context passing, and hacked-together endpoints. The community recognized that LLM-centric architectures needed a unifying protocol so that tool integrations could be plug-and-play, rather than unique engineering projects each time.
Why Model Context Protocol (MCP) Was Invented
The Model Context Protocol (MCP) was created as a direct response to these challenges of LLM integration. As described by Anthropic (who introduced MCP in late 2024), even the most advanced AI models were “constrained by their isolation from data – trapped behind information silos and legacy systems”, with every new data source requiring a custom integration. This fragmentation meant that building a truly connected AI assistant (one that can draw on all relevant knowledge in real time) was extremely difficult to scale. Developers found themselves reinventing the wheel for each tool: writing custom code, custom prompts, and custom authentication flows, which duplicated effort and introduced bugs and security risks.
MCP’s invention was motivated by the same principle that drove earlier standards: don’t repeat the integration effort for every pairing; instead, agree on a common protocol so that any client can talk to any service. In Anthropic’s words, MCP “provides a universal, open standard for connecting AI systems with data sources, replacing fragmented integrations with a single protocol”. The goal is to let developers build against a standard interface rather than maintaining separate connectors for each service. By doing so, the hope is that an ecosystem of interchangeable components emerges: if your AI agent speaks MCP, it can connect to any MCP-compatible data source or tool. This is very much akin to how SOAP standardized web service calls or how ODBC standardized database access – it makes the connector a one-time effort that can be reused across applications. As one commentator noted, “many in the community now see MCP as the likely winner in the race to standardize how AI systems connect to external data (much like how USB, HTTP, or ODBC became ubiquitous standards in their domains)”. That captures the intent: MCP as the USB-C port for AI, a universal plug for AI assistants and tools.
So what specific problems does MCP solve? First, it introduces a consistent method for an AI agent to discover and use tools. Instead of hard-coding how to call each API, an MCP-compliant server advertises its capabilities in a standard way. An AI client can query an MCP server to find out “what can you do?” and what format to use, similar to how a web service WSDL tells a client what operations are available. In MCP, this is done in a more modern, lightweight way (as we’ll discuss shortly), but the effect is the same: dynamic discovery. The AI doesn’t need prior training or coding for each new tool; if the tool has an MCP wrapper, the AI can plug in. For example, if a new CRM system comes online with an MCP server, an AI agent can automatically detect and use it via the standardized interface, “offering flexibility traditional approaches can’t match.”
Second, MCP provides a structured approach to sharing context with LLMs. This means not just issuing commands to tools, but also retrieving data (documents, records, etc.) in a format the LLM can incorporate into its context window. By defining standard message types for “resources” (data) and “tools” (actions), MCP makes it easier for developers to feed relevant information to the model when needed. Essentially, it helps solve the “knowledge cutoff” or context limitation problem: an AI that only knows its training data can now securely fetch live data on demand and incorporate it into its reasoning. This is crucial for producing relevant, up-to-date responses.
Third, MCP addresses security and infrastructure concerns that arise when connecting AI to sensitive data. In the wild early experiments, people sometimes gave LLMs access to tools by exposing API keys or connecting the model directly to databases – approaches that were ad-hoc and potentially dangerous. MCP, being designed with enterprise use in mind, includes best practices for securing data within your own infrastructure. The MCP server acts as a controlled gateway: it can enforce authentication, logging, rate limiting, and ensure the AI only sees what it’s permitted to. Because it’s a two-way protocol, it also allows for user-in-the-loop control if desired (e.g. requiring human approval for certain actions, or sanitizing outputs). This is reminiscent of how SOAP had robust security standards for enterprise use, but MCP aims to blend security with ease-of-use more akin to modern APIs. For example, OAuth support is being added to MCP so that an AI acting on behalf of a user can be properly authenticated to external services instead of sharing a single static token. Solving the “identity mapping” problem (i.e., clarifying who the AI is acting as when it calls an external service) is an active area in MCP’s evolution, precisely because trust and permissions have shifted to the client side.
In summary, MCP was invented to make LLM integration easier, more reliable, and more secure by standardizing the way AI clients connect to the tools and data they need.
What is MCP and How Does It Work?
At its core, the Model Context Protocol defines a client–server architecture for AI integrations. The naming can be a bit confusing at first because in an MCP conversation the AI-powered application is the “client” and the data/tool source is the “server” (reminiscent of traditional client-server, but here the client is an AI host). The major components are: MCP Servers – lightweight services that expose specific capabilities (e.g. a file repository, a calendar, a database) via the MCP standard; MCP Clients – connectors on the AI side that manage connections to these servers; and an MCP Host – the AI application or agent environment that initiates connections and orchestrates everything.
In practical terms, an MCP Server could be a small web service (perhaps running locally or in the cloud) that wraps a data source’s API, speaking JSON over a websocket or HTTP. The MCP Host might be an AI assistant app (like Anthropic’s Claude Desktop or a VS Code plugin) that knows how to load MCP client modules for each server and relay messages between the LLM and the server.
Under the hood, MCP uses a JSON-RPC 2.0 message format for communication. JSON-RPC is a lightweight remote procedure call protocol using JSON, which is simpler than SOAP’s XML but still provides a standard request/response structure. This means when the LLM (via the MCP client) wants to use a tool or fetch data, it sends a JSON-RPC request to the MCP server, which executes the action or query and sends back a JSON response.
The protocol supports both calls from client to server (e.g. “search for files matching X”) and asynchronous or streaming responses (for instance, a server can send progress updates or request additional info, thanks to JSON-RPC’s support for notifications). Importantly, MCP is stateless in the sense that each call is self-contained, much like a REST API call – the server doesn’t hold session state about the conversation, aside from perhaps a connection token. This stateless design aligns with the needs of LLM orchestration: the LLM maintains context in its own memory (or via the host application), while each tool interaction is a discrete transaction. The benefit is scalability and modularity; an MCP server can serve many clients and doesn’t need complex session management.
One way to understand MCP is to compare it to another successful standard: the Language Server Protocol (LSP). MCP’s designers explicitly took inspiration from LSP. LSP allows code editors and IDEs to support multiple programming languages through a standardized protocol – instead of building, say, Python support separately for VS Code, Sublime, and Vim, you write one Python language server and all editors that speak LSP can use it.
Similarly, MCP posits: instead of writing a custom “email plugin” or “database plugin” for every AI agent or every vendor’s LLM, write one MCP server for email, one for database, etc., and any MCP-enabled AI can use them. In LSP, the editor (client) asks the language server for things like autocomplete suggestions or code diagnostics. In MCP, the AI agent (client) might ask a data server for relevant documents or invoke a tool to perform an action. A key difference is that LSP is typically reactive (the editor only acts when a user types or saves, etc.), whereas MCP is designed for autonomous AI behavior. An AI agent can decide on its own chain of actions: “First, I’ll ask the Slack server if there are messages about this topic; then I’ll query the DB server for records; then I might use the browser server to find additional info.” MCP supports this autonomy by not assuming a human is initiating each request – the agent can plan and execute a sequence of tool calls as needed.
MCP Architecture and Features
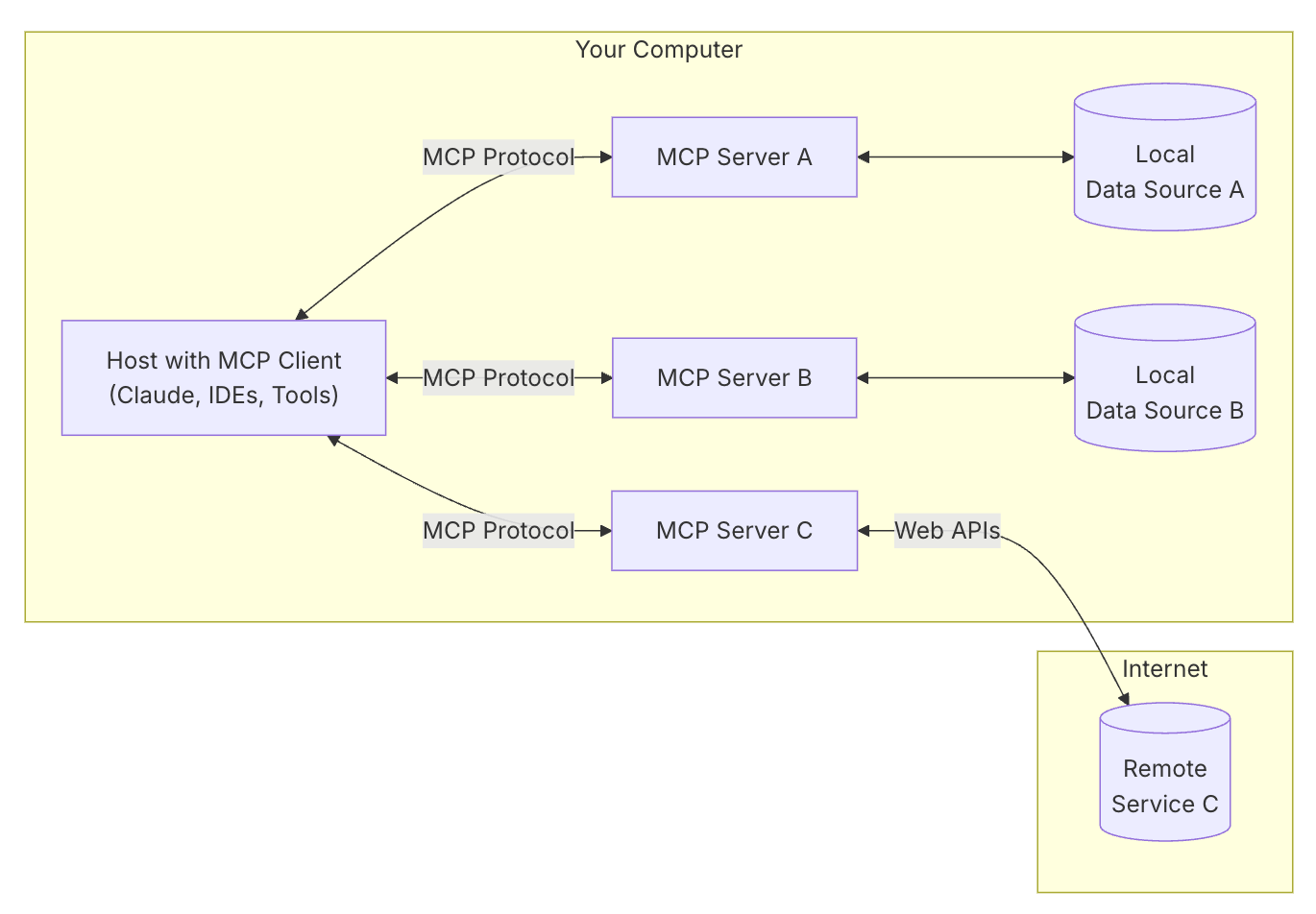
Figure 1: High-level overview of MCP’s client-server architecture (Image credit: Anthropic). The MCP Client (within an AI application) connects to one or more MCP Servers. MCP servers expose Tools, Resources, and Prompts.
- Tools are actions or functions the model can invoke (model-controlled, e.g. “retrieve/search”, “send a message”, “update a record”).
- Resources are data assets the server provides (application-controlled, e.g. files, database rows, API responses).
- Prompts are pre-defined prompt templates or instructions (user-controlled templates for common interactions, e.g. a prompt for document Q&A or a summary format).
The LLM-driven client can dynamically discover available tools, query for resources, and even request prompt templates from the server. Communication occurs via JSON-RPC messages over a secure channel, allowing two-way exchange.
In practical terms, when an MCP connection is established, the workflow is often as follows: the MCP Host will query the MCP Server for its available capabilities. The server replies with a description of the tools it provides (including their names and what parameters they expect), the types of resources it can serve (and how to request them), and any built-in prompt templates it offers. This is somewhat analogous to how a SOAP web service would publish a WSDL describing its operations, or how an OpenAPI (Swagger) spec describes REST endpoints – except it’s happening programmatically at runtime.
The LLM (or more precisely the agent framework around it) now knows what it can do with this server. From there, the LLM can choose to invoke a tool by sending a JSON-RPC request like:
{"method": "toolName", "params": { ... }}
The MCP client library on the host takes care of formatting these requests and handling responses, so the LLM might simply generate a higher-level command (sometimes even in natural language which the MCP client translates, depending on implementation).
Crucially, MCP’s design emphasizes that these integrations are composable and stateless. Each MCP server is focused on one domain (one data source or one type of tool) and can be developed independently. The AI agent can maintain context across multiple calls – for example, it might remember that it got a list of file IDs from a “Drive” server and then loop over them asking a “Database” server for details – but each server doesn’t need to know about the other. The context lives with the AI. MCP thus encourages a microservices-like style for AI tools: lots of small, specialized servers that the AI can draw from.
Another notable feature is bidirectional communication. Traditional REST APIs are request-response: the client always initiates. MCP (using JSON-RPC) allows for servers to send callbacks or streaming data back. For instance, a server could push a real-time update (“new data available”) or ask the AI a question (“I have multiple results, which one do you want?”) – effectively a mini dialog between the tool and the AI. While not every use case will need this, it’s powerful for real-time collaboration or long-running tasks. The designers highlight that MCP supports “real-time, two-way communication” as opposed to static one-off queries. This aligns with making AI integrations more dynamic: an AI could start a tool action and continue conversing with the user while progress events stream in from the tool, for example.
Security is also woven into the protocol. Since the AI agent might be running in a user’s environment, MCP is typically used in a way that the MCP server runs within the user’s trusted boundary or with controlled access. For example, an enterprise might deploy an MCP server that interfaces to their internal knowledge base; the AI (client) can query it, but the server ensures only authorized data is returned.
Because MCP is open and self-hostable, organizations are not forced to send data to a central AI service to use it – they can keep data local and just use MCP to bridge the AI to that data. This is a shift from earlier “AI plugin” models where, say, you’d have to give a third-party (like an OpenAI plugin) access to your systems. Instead, MCP lets you host the integration yourself and just expose it in a standardized way to any AI you choose.
The Block CTO, Dhanji Prasanna, touched on this, emphasizing open technologies like MCP as “bridges that connect AI to real-world applications” in a collaborative, transparent way. By being open-source and infrastructure-flexible, MCP appeals to those who want to avoid vendor lock-in and maintain control. In fact, one of MCP’s selling points is flexibility to switch between LLM providers – since MCP is model-agnostic, you could use Anthropic’s Claude today and an open-source LLM tomorrow, and your MCP tool integrations would remain the same. This decoupling of the “AI brain” from the “tools” mirrors the decoupling SOAP/REST did between client and server implementations.
To summarize MCP’s technical essence: it provides a standard schema and communication pattern for LLMs to extend their capabilities beyond their trained knowledge, by talking to external services. It turns various data sources and functionalities into modular, discoverable “plugins” that any compliant AI client can leverage.
Table 1 highlights some differences between the MCP approach and traditional API integrations (as commonly done before MCP):
Table: MCP vs Traditional API Integration
| Feature | MCP (Model Context Protocol) | Traditional APIs (pre-MCP) |
|---|---|---|
| Integration Method | One standardized protocol for all tools (unified interface) |
Custom integration per tool (each API different) |
| Communication Style | Real-time, bidirectional (two-way messaging, streaming updates) | Typically request–response only (client calls, server returns) |
| Tool Discovery | Automatic & dynamic – AI can discover available tools/capabilities at runtime | Manual configuration – tools must be pre-integrated or coded in |
| Context Awareness | Built-in support for sending context (documents, user data, etc.) through “Resources” and shared prompts | Limited or none – each API handles context differently, often not aware of AI context |
| Scalability of Integrations | Plug-and-play expansion – adding a new data source just means running a new MCP server (minimal changes to AI client) | Linear integration effort – each new tool requires significant development and maintenance |
As shown above, MCP aims to streamline development and maintenance. By reducing custom glue code, developers can focus more on the AI logic and less on API fiddling. Early adopters report faster development cycles: instead of spending days writing a connector, they can drop in a pre-built MCP server or quickly generate one using an SDK. In fact, Anthropic demonstrated using Claude itself to help write MCP server code, accelerating integration development. The protocol’s emphasis on dynamic discovery and stateless use also means it fits well with the on-demand nature of LLM queries – the AI can call a tool when needed and not worry about setup/teardown beyond establishing the connection.
The Client-as-Orchestrator Model: Trust and Compute Shifts
One of the most profound implications of the MCP-enabled architecture is the shift of trust and compute to the client side. In a traditional app, the server was the source of truth and decision-making; clients were generally not trusted beyond the basics (which is why servers validate everything). Now consider an AI agent running in a user’s environment (the client): it might have wide-ranging access via MCP to read files, query databases, send messages, etc. We are effectively empowering the client with far more autonomy and capability than before. This raises the question: how do we ensure the AI uses these powers correctly, securely, and in alignment with user intent? The trust model is being rewritten.
From a compute perspective, the heavy lifting of understanding the user request and determining the action plan is done by the LLM on the client. This can be computationally expensive (LLMs are far heavier than typical client code), but thanks to advances in cloud and on-device AI, it’s becoming feasible. Some architectures keep the LLM itself in the cloud but conceptually treat it as part of the “client side” (for instance, ChatGPT plugins use OpenAI’s model in the cloud as the orchestrator calling out to plugin APIs). Whether the model is local or remote, it’s the role that matters: the model is acting as the user’s agent, not as a backend service.
The compute burden thus shifts – servers become relatively lightweight (just fetching or executing specific tasks), while the model chews through unstructured data, instructions, and planning. In a sense, the client side is doing what multiple backend microservices and an orchestration layer would have done in earlier architectures. This can simplify back-end infrastructure (since each service can be dumb data providers), but puts more stress on the model’s performance and context management.
From a trust and security perspective, MCP and similar approaches demand careful design. The client/agent needs appropriate credentials to access each MCP server (e.g. your AI needs to prove it’s you to the email server). Solutions like OAuth delegation, API keys, or embedding the AI within the user’s authenticated session are used. But as the Botpress team pointed out, without clear identity mapping the question arises: is the AI acting “as the user” or as an independent entity with its own account?
If an AI agent is helping a user, ideally it should use the user’s permissions (so it can only access what that user could). Implementing this in a standardized way is non-trivial – it’s an ongoing evolution in MCP’s spec. In traditional client-server, the server was the gatekeeper (it knew the user’s session and enforced rules). In client-orchestrator, the AI might connect to many services, each needing to enforce rules possibly without knowing the full context. Trust is distributed: each MCP server must trust that the AI client is properly authorized. This is why having a protocol helps – it creates hooks for passing along auth tokens and auditing usage in one place rather than a hodgepodge.
There’s also the angle of control and oversight. With the AI making decisions, sometimes enterprises want a way to monitor or constrain those decisions. MCP’s design allows for human oversight loops – for example, an MCP server could require confirmation for a destructive action, or a logging service could record all tool invocations for review. These are analogous to how servers log and control client actions in traditional setups, but now the focus might be on the AI’s decision process. Some have called this a “human in the loop” capability – MCP even has provisions where an MCP server can essentially ask the AI to get clarification from a human user if needed. This reflects an understanding that an AI orchestrator could benefit from sanity checks, especially in critical domains.
Despite these challenges, the shift of trust to the client has a positive flipside: data locality and privacy. Instead of sending your database contents to an AI vendor to fine-tune a model, you can keep data in-house and let the AI come and query it via MCP on a need-to-know basis. The AI (if it’s an external model) only sees the specific answers or snippets it asked for, not the entire dataset. This minimizes exposure of sensitive info.
Many companies prefer this model – they retain control of data storage and just expose an interface for the AI to retrieve what it needs. It’s analogous to how in the 2000s companies were reluctant to open direct DB access but would expose controlled services; now they can expose an MCP service to the AI. The trust is that the AI’s requests will be appropriate – which comes down to how well the AI is instructed and any policy in the MCP client to prevent misuse. For instance, an organization might configure the AI agent to disallow certain tool calls (maybe block an “email send” tool for certain user roles) to maintain governance.
In summary, the client-as-orchestrator model reimagines the division of responsibilities: The front-end (AI + MCP clients) handles the intelligence and workflow – deciding what needs to be done – while the back-end (MCP servers) handle doing it and enforcing low-level access rules. This is almost the inverse of a typical web app where the front-end only decides how to display things and the back-end decides what to do.
With MCP and LLMs, the front-end is empowered to be the decision-maker. This inversion is powerful, enabling extremely flexible apps (since the AI can adapt to new goals without new server logic), but it requires a solid protocol like MCP to ensure all the pieces communicate correctly and securely.
Conclusion
The shift from traditional client/server architectures to an LLM-centric, client-orchestrator paradigm represents a significant re-balancing of how we build and distribute intelligence in software systems. In this new paradigm, the client (empowered by an AI model) takes on responsibilities once held exclusively by servers: integrating data from multiple sources, deciding on courses of action, and dynamically adapting to user needs.
The Model Context Protocol (MCP) has emerged as a timely innovation to support this shift. Much like how SOAP introduced a standard for heterogenous systems to communicate and REST brought scalable simplicity to web APIs, MCP provides a standardized, open interface for AI models to connect with the tools and data around them. It was invented to solve the pressing integration challenges in AI applications – reducing the friction of hooking up an LLM to ever more context sources – and does so by combining the lessons of past protocols (loose coupling, strong contracts, stateless communication) with features tailored to AI (dynamic discovery, prompt context, and two-way tool use).
Technically, MCP addresses the deep need for modularity and flexibility in AI systems. It lets us treat data sources and actions as interchangeable components that an AI can utilize at will, rather than fixed endpoints wired into an app. This brings software architecture closer to the ideal of being data- and capability-centric rather than application-centric – the AI agent can draw on any capability available in the network, unconstrained by application boundaries, as long as a standard connector (MCP server) is present.
The architectural balance indeed flips: where once clients were thin and servers omniscient, now the client-side AI is richly empowered and servers are specialized responders. Trust and compute have shifted accordingly, raising new challenges in security and design but also opening opportunities for more personalized and context-rich experiences (since the AI working on behalf of a user can integrate that user’s context across services in ways a siloed server might not easily do).
Developer and industry response to MCP suggests a strong appetite for such a standard. Early adopters in various domains (from coding assistants to enterprise data copilots) report that it simplifies development and unlocks faster innovation by removing the “plumbing” work from each project. As more tool connectors become available off-the-shelf, even small teams can equip an AI agent with a wide array of skills – similar to how a vast library of REST APIs enabled the explosion of mashup applications in the Web 2.0 era.
There is active discussion about making MCP or something like it a universal standard, with comparisons being made to USB-C for AI or the HTTP for AI data. At the same time, thoughtful critiques remind us that standards only thrive with broad support – MCP’s true test will be adoption beyond its originator. The coming year or two may see consolidation if major AI providers rally around MCP (or a compatible variant), or fragmentation if multiple protocols compete.
Regardless of the exact standard, the trend is clear: LLMs acting as orchestrators of modular tools are here to stay, and architectures will increasingly favor a client-centralized model for AI-heavy applications. Just as previous generations of computing saw shifts from mainframes to client-server, and then to cloud with rich web clients, we are now moving into the era of the AI-augmented client.
MCP is a crucial piece of infrastructure for this era, aiming to ensure that the transition is as smooth and powerful as possible – much like how SOAP and REST paved the way for the connected software ecosystems we now take for granted. In essence, MCP and similar efforts are building the connective tissue for the next phase of software: one where intelligent clients seamlessly tap into an ever-growing landscape of services, enabling applications that are more adaptive, context-aware, and capable than ever before.
Sources:
- Anthropic – Introducing the Model Context Protocol (Nov 2024)
- Anthropic – Model Context Protocol announcement (quote from Block CTO)
- ModelContextProtocol.io – Introduction and documentation
- HuggingFace Blog – What is MCP, and Why Is Everyone Talking About It?
- Spearhead.so – The USB-C Moment for AI: Introducing MCP
- Botpress Blog – Breaking Down Model Context Protocol (MCP)
- Medium (A. Bhuyan) – Standard Interfaces: Why WSDL/SOAP Still Matter
- Andreessen Horowitz (Y. Li) – A Deep Dive Into MCP and the Future of AI Tooling
- Daily.dev – What is MCP? (Comparison of MCP vs Traditional APIs)
- Superex Medium – MCP: bridge for AI to break free from data silos